State Encoders in Reinforcement Learning for Recommendation: A Reproducibility Study
Abstract
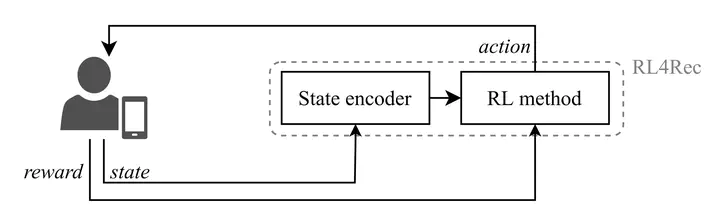
Methods for reinforcement learning for recommendation (RL4Rec) are increasingly receiving attention as they can quickly adapt to user feedback. A typical RL4Rec framework consists of (1) a state encoder to encode the state that stores the users’ historical interactions, and (2) an RL method to take actions and observe rewards. Prior work compared four state encoders in an environment where user feedback is simulated based on real-world logged user data. An attention-based state encoder was found to be the optimal choice as it reached the highest performance. However, this finding is limited to the actor-critic method, four state encoders, and evaluation-simulators that do not debias logged user data. In response to these shortcomings, we reproduce and expand on the existing comparison of attention-based state encoders (1) in the publicly available debiased RL4Rec SOFA simulator with (2) a different RL method, (3) more state encoders, and (4) a different dataset. Importantly, our experimental results indicate that existing findings do not generalize to the debiased SOFA simulator generated from a different dataset and a Deep Q-Network (DQN)-based method when compared with more state encoders.
Supplementary notes can be added here, including code, math, and images.
Jin Huang
Postdoc
My research interest focuses on trustworthy advice-giving systems for real-world applications, especially in high-risk domains, e.g., healthcare, news recommendation, and public services.